
Creating a PubMed, scientific literature recommendation engine
How I created a PubMed scientific literature recommendation engine using over 4 million paper abstracts downloaded from PubMed.

I wanted to create a recommendation engine, but I didn't want to just do a movie another movie recommendation engine. I wanted to do something a little more specific to my expertise. Instead I created a model to recommend you scientific literature. It follows a typical content-based filtering approach.
The Goal
Give a paper of interest (by PubMed ID), get back a set of suggested papers you may also like.
Data source
Being a publicly funded resource run by the NIH, all of PubMed's citation data is completely available online, and there is A LOT of it. Once per year they update the set in its entirety, and daily they upload updated files. It can all be acquired from here:
https://www.nlm.nih.gov/databases/download/pubmed_medline.html
I downloaded the entire PubMed collection of citation data. The only catch: its all in XML format and not every record has consistent fields.
I created a couple simple scripts to parse the XML files and convert the data into a more structured format.
Metadata extraction
import xml.etree.ElementTree as ET
import glob
import gzip
from tqdm import tqdm
import sys
import pickle
import pandas as pd
import json
import string
import numpy as np
import os
from multiprocessing.pool import Pool
ARTICLE_TYPES_WANTED = ["Journal Article", "Review"]
# Function to take one file
def get_article_metadata(file):
print(file)
tree = ET.parse(gzip.open(file))
root = tree.getroot()
metadata = []
for article in root.iter("MedlineCitation"):
collected_data = {}
pmid = None
article_title = None
journal_title = None
authors = None # separted list of author names
keywords = []
year = None
# PMID #
pmid = article.find("PMID").text
# JOURNAL NAME #
for title in article.iter("Title"):
journal_title = title.text
# ARTICLE TITLE #
for title in article.iter("ArticleTitle"):
article_title = title.text
# AUTHORS #
found_authors = []
for Author in article.iter("Author"):
try:
last_name = Author.find("LastName").text #data
except AttributeError:
last_name = ""
try:
first_name = Author.find("ForeName").text #data
except:
first_name = ""
found_authors.append("{} {}".format(last_name, first_name)) # data
# Join aurhots into a single stringified list
authors = ";".join(found_authors) # data
# KEYWORDS #
for Keyword in article.iter("Keyword"):
keywords.append(Keyword.text)
try:
keywords = ";".join(keywords)
except TypeError:
keywords = [""]
# YEAR #
for Year in article.iter("ArticleDate"):
try:
year = Year.find("Year").text
except:
year = np.nan
# PUB TYPE #
for pub_Type in article.iter("PublicationType"):
if pub_Type.text in ARTICLE_TYPES_WANTED:
metadata.append({
"pmid": pmid,
"Journal": journal_title,
"ArticleTitle": article_title,
"authors": authors,
"keywords": keywords,
"year": year
})
break
data = pd.DataFrame(metadata)
data.to_csv("MetaData/{}_metadata.csv".format(os.path.basename(file)), index=False)
if __name__ == "__main__":
files = glob.glob("PubMedData/*.gz")
files = sorted(files)
pool = Pool(processes=6)
pool.map(get_article_metadata, files)
print("Done")
Abstract extraction
import xml.etree.ElementTree as ET
import glob
import gzip
from tqdm import tqdm
import sys
import pickle
import pandas as pd
import json
import string
# Create a generator to open each file and yield dict(pmid=abstract) for each citation within the file
def get_pmid_abstract_data(files):
for file in tqdm(files):
tree = ET.parse(gzip.open(file))
root = tree.getroot()
for article in root.iter("MedlineCitation"):
pmid = None
abstract = None
for pmid_ in article.iter("PMID"):
pmid = pmid_.text
pmid = int(pmid)
for abstract in article.iter("AbstractText"):
abstract = abstract.text
if abstract:
abstract = abstract.replace("\t", " ").replace("\n", "")
abstract = abstract.translate(str.maketrans('', '', string.punctuation))
yield {"pmid": pmid, "abstract": abstract}
if __name__ == "__main__":
# Get list of files in the directory
files = glob.glob("PubMedData/*.gz")
files = sorted(files)
print("I found {} files".format(len(files)))
with open("abstract_data.csv", "wt") as csv:
csv.write("pmid,abstract\n")
for output in get_pmid_abstract_data(files=files):
if output['abstract']:
csv.write("{},{}\n".format(str(output['pmid']), output['abstract'].encode("utf-8", errors="ignore")))
I was then able to merge these outputs into a more structured data table which was much easier to work with.
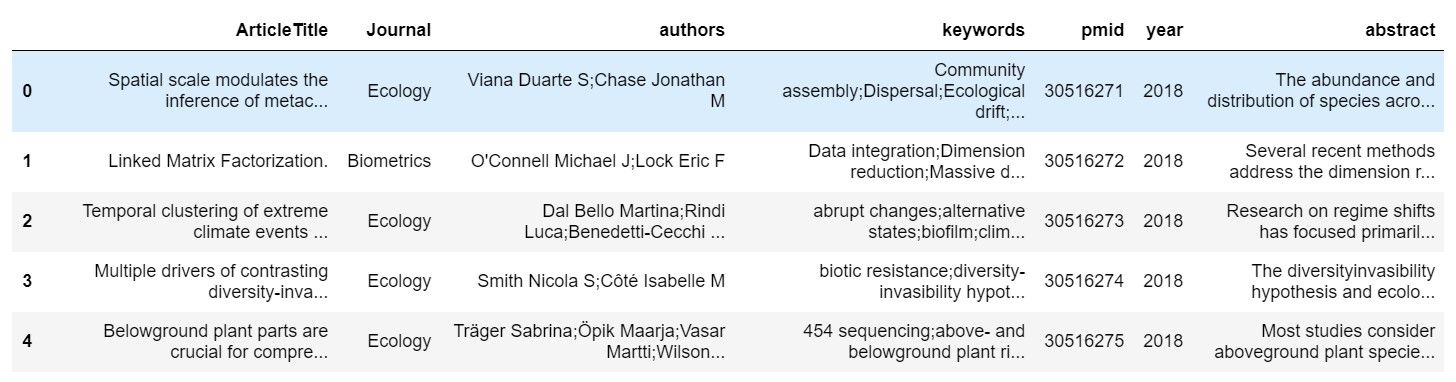
Data processing
With the exception of year and pubmed ID all of this data is text. So to create this recommendation engine I was going to have to use some natural language processing (NLP) techniques.
For each pubmed article I created a "soup" from all of the data contained in the table. Each soup was a list containing all of the text present in each column, stripping out punctuation and removing all capitalization.
For simplicity I am also only going to work with a subset of all of the pubmed citations, I am keeping approximately 4.1 million records.
These lists of words needed to be converted to numbers and I opted to use term-frequency inverse document frequency (Tf-Idf) weighting to de-prioritize terms found frequently in all articles. Scikit-learn has a TfidfVectorizer which can perform vectorization and weighting while simultaneously removing common stop words (a, an, the, etc.). Because I am working with 4.1 million PubMed citations, I also opted to only keep the top 20,000 features to keep the resulting matrix reasonable in size.
from sklearn.feature_extraction.text import TfidfVectorizer
tv = TfidfVectorizer(stop_words="english", max_features=20000)
matrix = tv.fit_transform(soups)From this very large and very sparse matrix you can do a pretty cool technique called Latent Semantic Analysis (LSA). It is way to decompose the matrix to reduce the number of features but still maintaining the general structure by 'combining' terms or sets of terms which have similar meaning. Again I used scikit-learn to perform this.
from sklearn.decomposition import TruncatedSVD
svd = TruncatedSVD(n_components=150) # this can be adjusted to find best performace
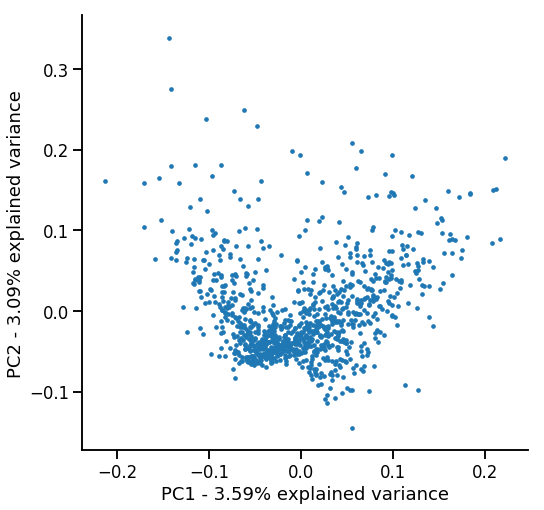
X = svd.fit_transform(matrix)To get a feel for what is happening, we can reduce the dimensionality (150) of the data to visualize it in two dimensions using PCA.
Finding recommendations
I tried a couple different techniques to actually calculate the recommendations. I tested calculating the Cosine Similarity between a given document and the rest of the matrix and using a NearestNeighbors model from sklearn.
Cosine Similarity was a little more memory efficient, but slower because you have to sort the results to find the most similar documents. NearestNeighbors was faster after training, but required a decent amount of RAM to hold the trained model in memory.
Performance-wise they seemed identical, but I can only test a small number of papers manually. Each would need to be deployed and get feedback logged from users to truly know if one provides the best recommendations.
Below I give a few details as to how I used one of the approaches
Nearest Neighbors approach
Using scikit-learn's NearestNeighbors you can fit the SVD matrix. You then give it a 1D vector representing a single document, and it will return a set of the most similar documents.
from sklearn.neighbors import NearestNeighbors
nbrs = NearestNeighbors(n_neighbors=5, n_jobs=-1).fit(X)Then we can feed it a document in the 1D SVD format and it will return the indicies of the most similar documents.
# I created dictionaries to store the PMID -> index and index -> PMID mappings called indicies and pmids
# Get the index from the pubmed id
index = indicies[26890697] #26890697 is the PubMedID
document = X[index].reshape(1,-1)
dists, ind = nbrs.kneighbors(document)
# Get the PubMedIDs from the returned indicies
suggested_pmids = pmids[ind]
Lets see how it performed.
Recommendation Results
Paper I asked for recommendations for:

Top recommendations from the model:




That is honestly pretty impressive. Judging by the title alone those are pretty decent paper suggestions.
Conclusion
Overall this was a pretty educational experience creating this recommendation system. It was my first major attempt at working with unstructured text data and using NLP machine learning techniques.
I did actually create everything needed to deploy this model into production. I utilized Flask (backend), React (user interface), and MongoDB (NoSQL database).
It worked with a user inputting a PubMed ID of interest. The Flask backend would then load the required data, calculate the recommendations, get the PubMed IDs of the top 5 recommendations, fetch the paper details from the NoSQL database, and return that to the user. Additionally, the app would then store those recommendations with the paper in the database, so the calculation would not have to be performed again.
As a calculation for each recommendation is pretty resource heavy for a short period, I created a job queue using Redis and Redis-Queue to keep system resources under control.
I even packaged the whole app as a Docker container so it could be easily deployed or scaled as needed. Just throw a Load Balancer in front and scale the number of containers as needed. The only standalone infrastructure the app needed was the NoSQL database instance that each container could connect to.
But in the end I couldn't justify spending the money needed to deploy this hobby project. I estimated it would be about $20-$30 a month to have a minimal working prototype up.
But maybe one day I will throw it up and try to get some feedback on the recommendations.