
Rescuing a 12TB RAID5 array from the brink of disaster
I rebooted the system and mdadm was reporting one drive was missing. Weird. It was just working 10 seconds ago. I know it's good. It has served faithfully for a few thousand hours so far. It just passed all of its SMART tests yesterday. This drive has not failed. Why did it disappear from my array?

I had spent 24+ hours syncing the array filling it with data... I rebooted... It was gone.
How I got here
I run a small server in my house that primarily functions as a media server and a NAS. It came from very humble beginnings. I originally built it with some spare parts I had laying around which included an old 3.5in 500GB hard drive. That drive eventually died and was replaced with a 1TB 2.5in drive.
Not wanting to keep the OS and media on the same drive, I opted to store most of the media on an external HDD. With USB 3.0 it was fast enough, but knowing 2TB (and growing by the day) of media was kept safe only on an external hard drive did keep me up at night.
I eventually did the right thing and purchased a new 4TB internal HDD for this server and copied over all of the data. It felt much more secure. Data safe and sound.
But drives do fail. I was keeping the data backed up with the external drive, but a drive failure would still mean a loss of some data. In addition to the downtime of having to replace the drive and restore the data. The thought of having a little redundancy was a nice one.
An array of mistakes
So I purchased 2 more 4TB drives for the server. I wanted to set up these 12TB of raw storage into a RAID5 configuration which would give me 8TB of useable space and provide some parity so that I could suffer one drive failure and still recover the data. This combined with regular data backup made me happy.
Because as the internet will loudly tell you. RAID IS NOT A BACKUP.
I backed up all of my data from the current sole internal drive and I followed this wonderful guide and started the painfully long process of creating/syncing the new RAID5 array with the two new drives. I didn't bother to erase or format the current drive because I assumed the RAID creation would wipe the disk anyway [mistake #1]. Following the guide I setup mdadm.conf, updated the initramfs, and added the array to my fstab. I was eager to continue to get this setup and running. So instead of rebooting and checking the raid automatically came online, I just started copying the data backup to the drive [mistake #2].
Another 12-14 hours later all of the data has been restored to my new RAID5 array. I updated permissions that were lost during the backup, set all of my media server services to the new drive paths, and updated my NAS mount points. Everything was working beautiful and looking great.
I finally rebooted
So after all of this I finally rebooted the system. The RAID didn't mount.
Thats weird...
Mdadm was reporting one drive was missing from the array. Weird. It was just working 10 seconds ago. Additional digging showed the missing drive was my original drive in the system. I know it's good. It has served faithfully for a few thousand hours so far. It just passed all of its SMART tests yesterday. This drive has not failed.
I kept digging. Having mdadm inspect individual drives eventually gave information indicating the superblock were missing from this drive. How is this possible? It was just created yesterday. The whole RAID was working prior to reboot. It was like mdadm just didn't write the superblock to this drive at all.
I did not think it was a coincidence that this drive missing the superblock was the one that was originally in my server. Scouring the internet led to some reports of similar, but not identical, problems occurring with mdadm to other people. But these problems were mostly left unanswered and unresolved.
A risky solution
So two drives were still good, and the data is backed up. This gave me enough comfort to take a few risks here.
Running fdisk -l on all 3 RAID drives gave me one clue. The drive missing had one label the others did not: Disklabel type: gpt.
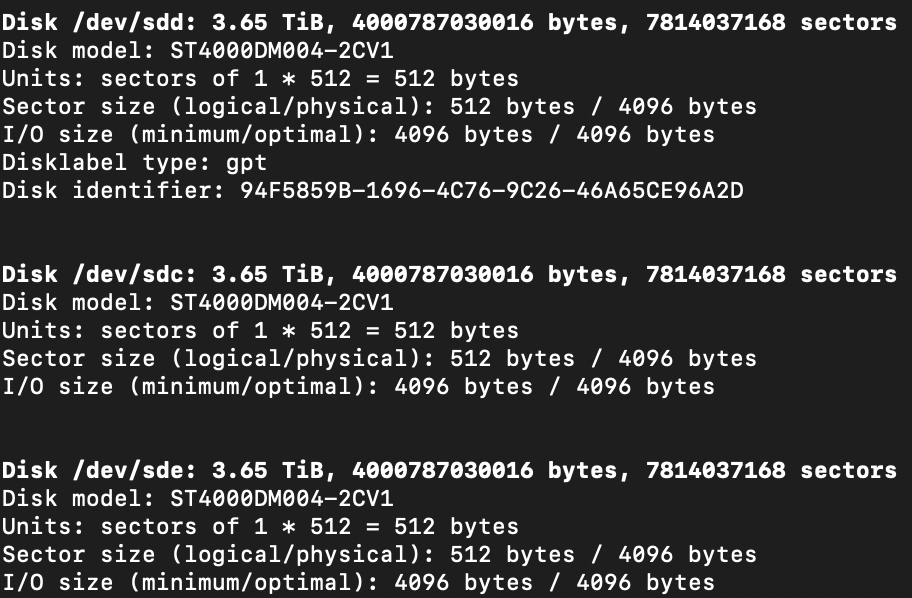
So with this drive is reporting a GPT partition table while the new ones are not AND me not wiping this drive at the beginning felt like there might be something to this.
So I wiped the partition table from this drive:
dd if=/dev/zero of=/dev/sdd bs=512 count=1I then recreated the array.
sudo mdadm --create --verbose /dev/md0 --level=5 --assume-clean --raid-devices=3 /dev/sdc /dev/sdd /dev/sdeI knew the array data was actually good and still there, so I was able to pass the --assume-clean flag. This caused only array metadata to be rebuilt, and avoid the 12+ hours of rebuilding the array. Additionally this resulted in all of the data being right on the drive where I left it.
After updating the mdadm.conf, initramfs, and fstab I rebooted the system.
This time, it came online. RAID assembled and mounted.
Conclusion
I have not been able to actually figure out what happened. Everything worked, looked totally normal, and reported no errors. I can only assume this is some bug in mdadm. During the initial RAID creation, mdadm acknowledged the partition table present on the drive, and warned me it would be destroyed. This is what I wanted to happen so I assumed all was good.
But from the looks of it, mdadm did not actually do it. Or if it did, it failed to write the superblock in it's place.
When creating the array after zeroing the partition table on the drive, this warning did not appear and it wrote the superblock as it should.
So I can't explain why this happened, hopefully this solution will be of benefit to someone else one day.